Promoting Our Data Testing Paradigm with Internal Serverless Websites
For companies wanting to share repositories or internal information in a secure manner, hosting websites internally is a must. So when our team faced the need to host internal static websites and did not have a clear company standard as to how to do so, we set out to establish our own.
With great data comes Great Expectations (Framework)
Providing a data-centric product under demanding service-level agreements requires repeatable data testing. We recently converged on the Great Expectations Framework to run dataset-specific assertions on every data set we ingest.
The Great Expectations Framework includes features to make your data testing journey as seamless as possible. One capability is a visual documentation tool, aptly named Data Docs, that renders the results of past data tests as HTML.
We use Great Expectations to provide comprehensive data tests to proactively identify issues in our data pipeline. This ensures that discovering and fixing data issues is fast and reliable, allowing us to consistently provide data quality at the level our customers expect.
Of course, fixes sometimes require a cross-team collaboration that involves both technical and non-technical users. To allow our non-technical users to independently remedy data issues, we need to provide them with enough information to understand why the data test failed. This requires us to provide visual feedback for every dataset’s test run.
Data Docs are therefore a perfect fit. Given the sensitive nature of the data and tests at hand, the Data Docs need to be hosted internally.
Generalizing the use case
While researching options to host Data Docs internally, we learned of other teams needing to internally host static data. An important feature for this use case is the ability to list the website’s files in an indexed format through a URL.
We settled on finding a common way to address both use cases. We’d look for a custom storage solution that: a) we could point to using a DNS and parse without compromising security, and b) would allow us to keep the websites internal. Both teams wanted to keep the hosting simple in order to avoid tremendous development and maintenance overhead while alleviating cognitive overhead on whoever needs access to said information.
Final requirements
Our final common solution should then:
- Serve web pages residing on S3 (HTML, CSS, and JS files)
- Be discoverable via DNS but only through an internal VPN, and
- Support HTTPS or the ability to add an SSL Certificate for secure access without each use case needing its own certificate definition.
To make the solution extensible to future use cases, we also needed to create a framework that allows us to add and maintain internal sites with minimal effort – ideally through a configuration-driven environment.
Establishing the company standard
Our Ultimate Hosting Solution
We ended up centering our solution on an Amazon Virtual Private Cloud where we hosted an ECS instance with a Fargate Task. The Fargate contains a NGINX instance that loads and renders our websites from their designated folders or buckets. Inside the Virtual Private Cloud, we added a single instance of Amazon ALB for its SSL and firewall support. On the routing side, we kept Amazon Route 53 from a previous research iteration as our DNS, due to its scalability in serving multiple nested private subdomains (or zones).
Not only did adding the Fargate Task allow us to meet our staticity requirement, but it also made the setup serverless and, therefore, easier to maintain.
On the storage end, we had to ensure that our S3 storage setup and separation of IAM roles did not interfere with the loading or access of the website. So we configured IAM-based VPC access on specific buckets for internal static web hosting to allow the Fargate Task to browse said buckets.
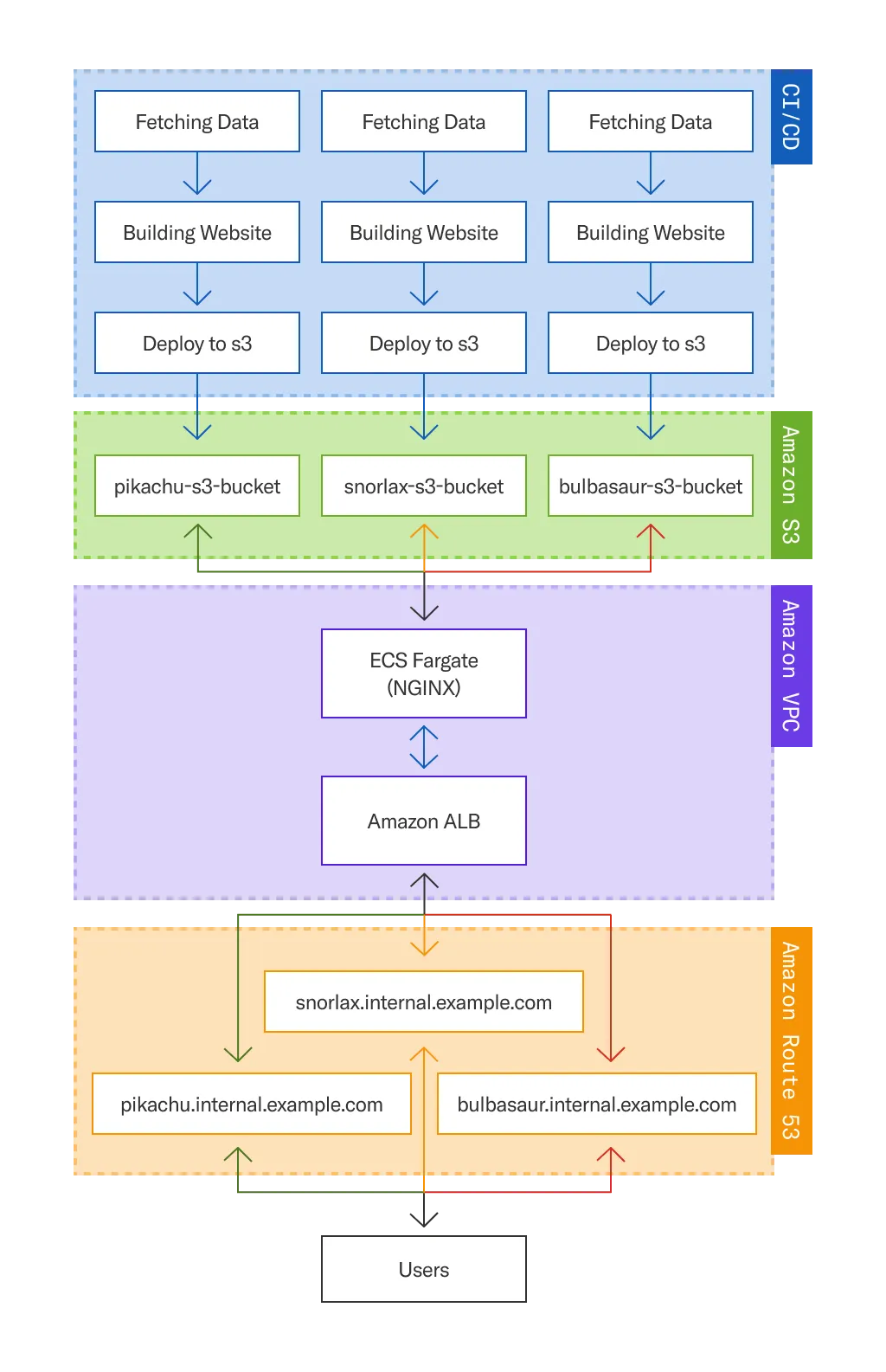
The solution solved our internal static hosting need, but having to configure S3 and Route 53 for each of our websites would still take some development overhead. Luckily, we could minimize the effort through a configuration-driven approach for our framework.
The Hosting Framework
To alleviate maintenance and development overhead on current and future use cases, it was important to lessen the amount of work to be done from the ideation of the use case to its proof of concept. And leaving the CI/CD logic and mechanism up to the website’s internal owners, we consequently focused on ensuring the following:
- Our VPC environment was pluggable on any bucket it was tasked to map
- A website storage entity (i.e. a new and standalone S3 bucket) would be easy to create and map to
- A new DNS route on our Amazon Route 53 private zone would be easy to create and map
With the VPC being a one-time internal configuration, we decided to concentrate our efforts on creating:
- A Terraform configuration template so that our S3 buckets were private, had “Static Website Hosting” enabled, and granted read access to our VPC
- A Terraform configuration template for a DNS record to point to our internal Load Balancer
- An NGINX configuration template to proxy pass our S3 bucket’s URL on our new DNS name
- A CI process that automatically validates and applies new configurations
Finally, to make the method of hosting an internal website more accessible to anyone within the company, we wrote an internal how-to guide, including all the required code templates for a quick copy-paste and plug-and-play approach, finally closing the requirement loop.
Other options we researched
The Gitlab Pages Route
With our self-hosted instance of GitLab, it initially made sense for us to look at the use case of GitLab CI to build and deploy Data Docs to GitLab Pages internally. We already had experience with this particular paradigm as we previously developed and maintained a custom dataset-centric metrics dashboard on GitLab Pages.
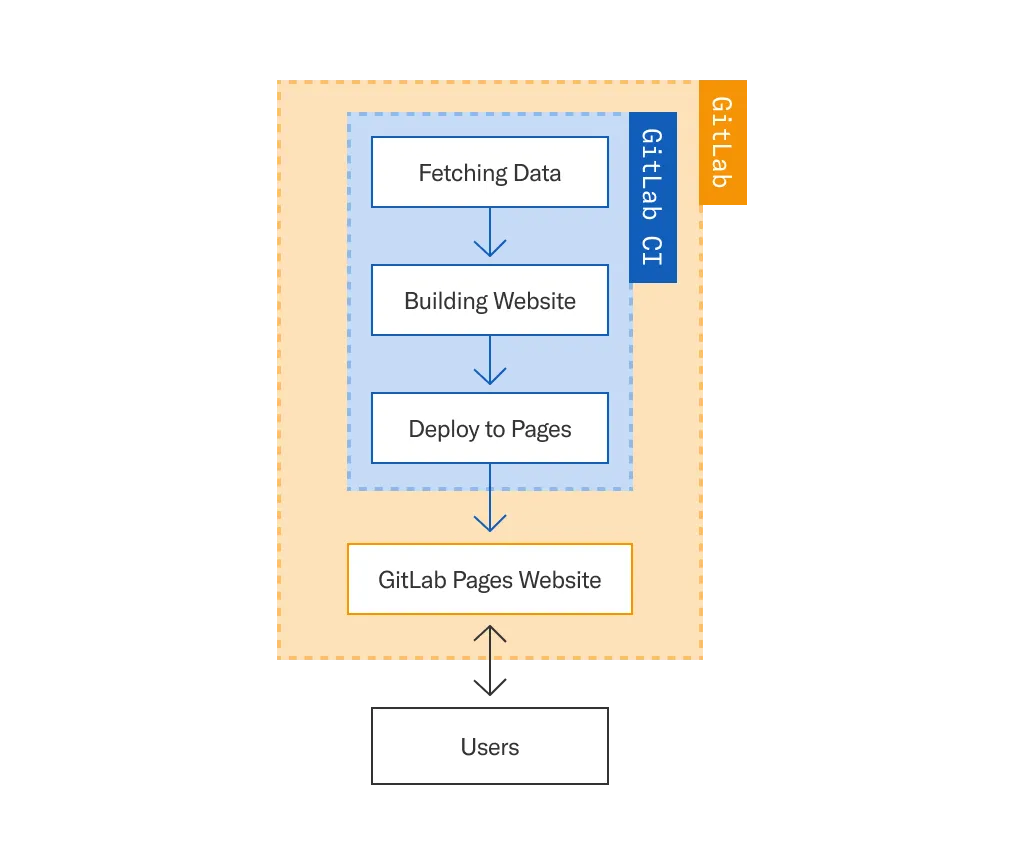
During our feasibility research for Data Docs, we encountered a complication where GitLab Pages’ deployment had to be triggered through CI. In contrast, our implementation of Great Expectations runs in a Python context under Airflow, and Data Docs has to be refreshed at each run of Great Expectations.
A solution we could have gone with in this paradigm is to have each run of Great Expectations trigger GitLab CI to recalculate and redeploy Data Docs. However, assuming the scenario where two or more data ingestion and validation pipelines run simultaneously, both pipelines would be attempting to trigger their respective runs of Data Docs calculation and deployment. That concurrency could have unforeseen volatility around Data Docs’ deployment output: it could technically invalidate the assertion process and its logs and create delays due to mandatory, manual verification of the Data Docs render. We therefore decided to research more hands-on paradigms that could accommodate our needs.
Using a DNS to Point Directly to Amazon S3
We use AWS extensively, so we looked at the tooling we already use on a daily basis. Given that Amazon S3 has the option of hosting a static website, our initial idea was to use Amazon Route 53 as a DNS to point to an Amazon S3 bucket.
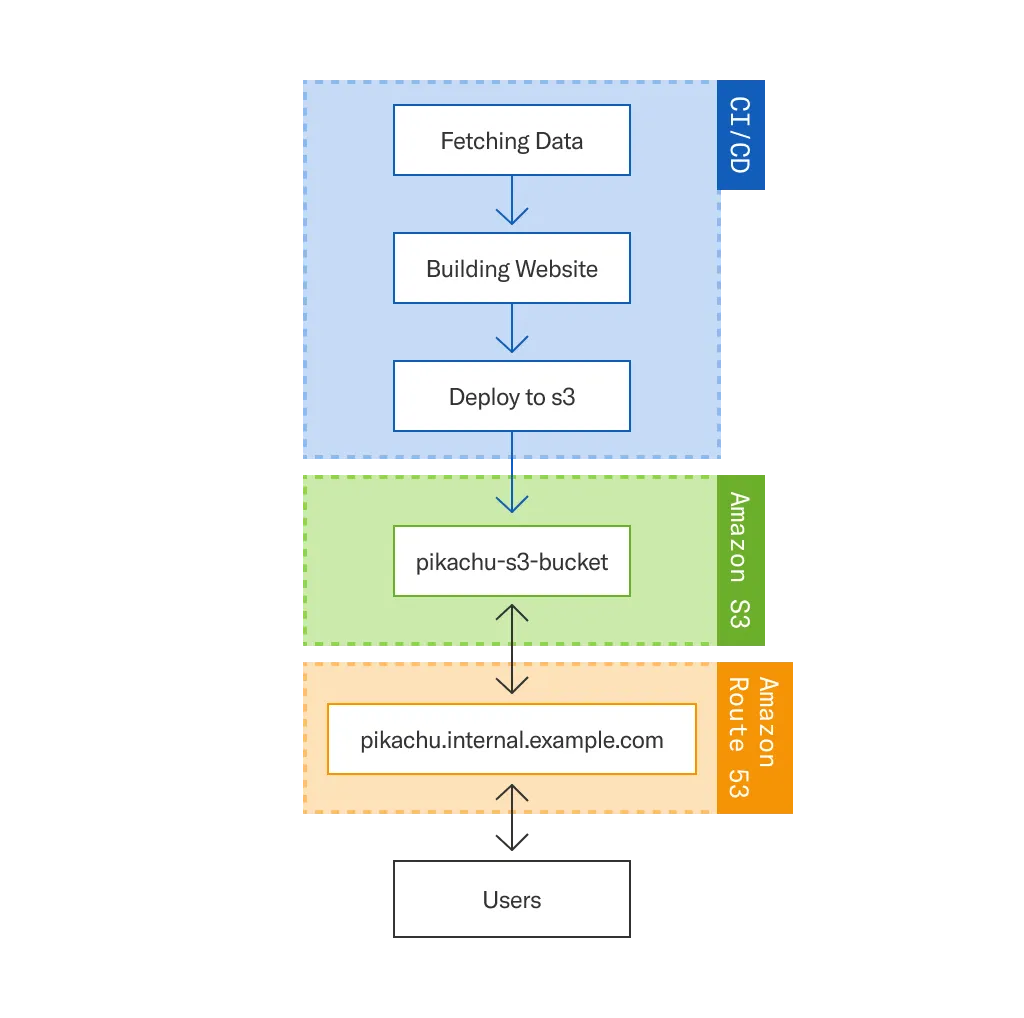
We steered away from this option because S3 neither supports HTTPS nor does it accept requests made from a different domain.
Using Amazing Cloudfront
Fortunately, we found a way to solve the issue using Amazon’s CDN, CloudFront. This allowed us to add HTTPS support to our S3 elements.
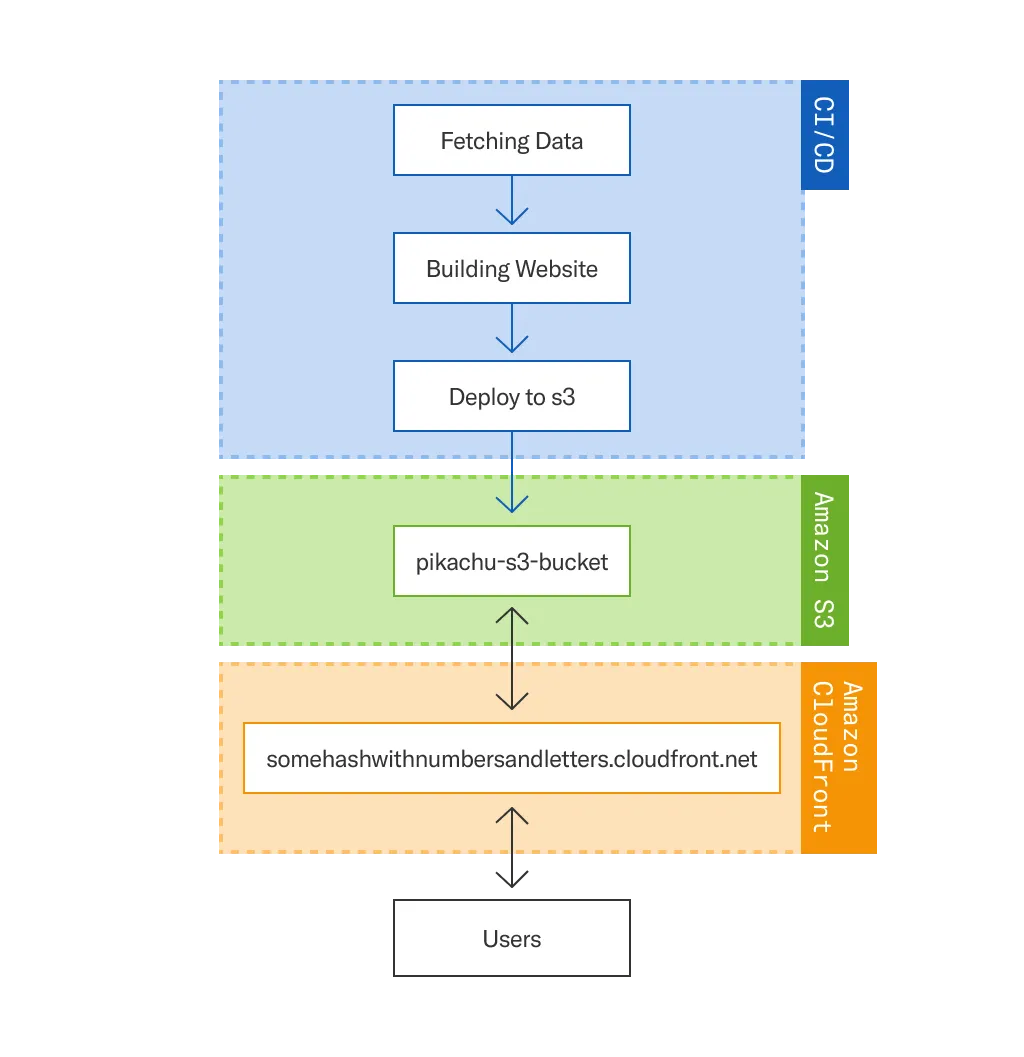
After further investigation, we had to forgo this path: CloudFront is only able to serve S3 content through the public domain, potentially exposing the files and information we would put in our S3 buckets.
Conclusion and next steps
From initial research to proof of concept and then adoption, the whole process was a true multi-team effort involving various Enigma stakeholders from Tech Ops, Web Developers and Data Engineers. This new infrastructure is already bearing fruit, both in terms of impact and adoption: we have already built the two previously mentioned use cases and migrated a pre-existing project from GitLab Pages.
A “nice to have” for convenience would be automating the template generation and mapping through CI. Making the process of hosting a full-on internal static website as simple as populating variables such as a bucket name, website name and homepage file name would truly make it easier and faster for our less-technical users.