The Secret World of Newline Characters
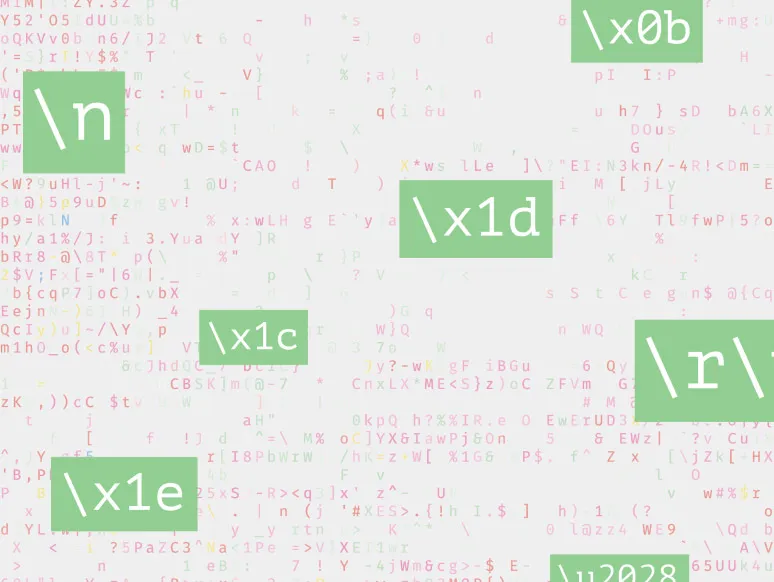
While fixing a recent regression in Enigma Public’s CSV ingestion (a few perfectly fine CSVs were now being rejected), I stumbled upon some curious discrepancies among Python idioms for handling newline characters. This led me down a rabbit hole of computing history and a world of exotic newline specimina so riveting that, at my colleague Eve’s suggestion, I figured it’d be worth sharing them.
The first thing to know about newlines is that, even in quotidian computing, they have many character representations. Each of the three traditional operating systems uses a different one:
\n Unix and Linux style,
\r\n Microsoft Windows style, and
\r the somewhat rarer MacOS classic style,
where \n and \r are conventional escape sequences for the ASCII characters Line Feed (LF) and Carriage Return (CR), respectively. Already, one should question why the Windows style employs two characters whereas the others get by with just one. This in fact harkens back to typewriter convention, in which a newline involves two actions: returning the carriage to the left-hand side, and advancing the paper by one line.
These three ASCII sequences account for newlines in nearly all plain-text documents, certainly amongst those you might email around or download from the web. So despite the occasional hiccup, modern cross-platform software has a pretty good handle on newlines, and Python is no exception. It has a concept of universal newlines which treats all variants with egality. Furthermore, the documentation for Python’s CSV reader recommends a single preferred way of dealing with universal newlines.
Sometimes Python tries to be extra helpful. Suppose you have a multi-line string that needs to be split, wherever newlines occur, into multiple lines. Fortunately there’s an aptly-named str.splitlines function to do exactly that, which you invoke and lo and behold, everything just works. So you send the strings to the CSV reader that prefers to receive individual lines one by one, and everything just works. And by the way, Requests (easily in the top-five most widely used Python libraries) also calls this function when you ask it for lines, and everything just works.
Then one day everything doesn’t work, at which point you double-check the docs and realize str.splitlines has its own ideas about what a newline can be:
\\n Line Feed (LF)
\r Carriage Return (CR)
\r\n Carriage Return + Line Feed (CR+LF)
\x0b Line Tabulation (VT)
\x0c Form Feed (FF)
\x1c File Separator (FS)
\x1d Group Separator (GS)
\x1e Record Separator (RS)
\x85 Next Line (NEL)
\u2028 Line Separator (LS)
\u2029 Paragraph Separator (PS)
Look, three may or may not be an acceptable number of newline variants, but eleven is definitely, unequivocally too many. Why would anyone need such multiplicity? Anyway, if you just want to keep the CSV reader happy, you’d find a way to just write the code to split lines without calling str.splitlines and get on with your day. But if you’re me, you end up trawling the internet for the origin story behind every side character on this list (and then writing that code).
So here’s the result of that trawl.
__________________________________________________
In 1963, the ASCII standard defined a character encoding for teleprinters, based on existing telegraph codes. The aforementioned LF and CR are part of the set of ASCII control characters, and among str.splitlines()’s list of newlines, five other control characters hail from this same set. Mr. Lammert Bies provides elucidating descriptions for them:
Line Tab a.k.a. Vertical Tab
“The vertical tab is like the horizontal tab defined to reduce the amount of work for creating layouts, and also reduce the amount of storage space for formatted text pages. The VT control code is used to jump to the next marked line.”
In the world of typewriters, a vertical tab typically moved a distance of 6 lines, the same way a horizontal tab would typically move a distance of 8 spaces. In old printers, the vertical tab would also speed up vertical movement by indicating a jump to the next spot on a special tab belt, which was helpful for aligning content on forms.
Form Feed
“The form feed code FF was designed to control the behaviour of printers. When receiving this code the printer moves to the next sheet of paper.”
File Separator
“The file separator FS is an interesting control code, as it gives us insight in the way that computer technology was organized in the sixties. We are now used to random access media like RAM and magnetic disks, but when the ASCII standard was defined, most data was serial. I am not only talking about serial communications, but also about serial storage like punch cards, paper tape and magnetic tapes. In such a situation it is clearly efficient to have a single control code to signal the separation of two files. The FS was defined for this purpose.”
Nowadays we still need a way to delimit files within a serialized stream, for example when uploading photos on a website. But how do we get around the fact that each file, especially a non-text image file, could itself contain the FS character? The MIME spec calls for a custom-defined boundary, and suggests using an improbable string of gibberish:
Content-Type: multipart/mixed;
boundary=gc0p4Jq0M2Yt08jU534c0p
Group Separator
“Data storage was one of the main reasons for some control codes to get in the ASCII definition. Databases are most of the time setup with tables, containing records. All records in one table have the same type, but records of different tables can be different. The group separator GS is defined to separate tables in a serial data storage system. Note that the word table wasn’t used at that moment and the ASCII people called it a group.”
Record Separator
“Within a group (or table) the records are separated with RS or record separator.”
We occasionally see CSV-ish files that use RS to separate records, which at first sounds defensible but honestly doesn’t really help, because CSV authors just want to hit the enter key. And now your CSV parser has to support yet another newline.
__________________________________________________
In the late 1970s, ASCII was extended by the ANSI standard to include additional control characters—to differentiate, the former are called C0 controls, the latter C1 controls. Using these new-fangled computer terminals of the day (such as 1978’s VT100) could draw primitive graphics at arbitrary cursor locations. Aivosto Oy takes us on a helpful tour of these:
“According to ANSI, the C1 controls were intended for input/output control of two-dimensional character-imaging devices, including interactive terminals of both the cathode ray tube and printer types, as well as output to microfilm printers.”
Evidently, the authors could not resist adding in a new-fangled newline amongst this fresh batch of characters.
C1 Next Line
“LF, having two alternative functions, has been a major source of confusion. While LF was initially defined as a “move down” operator, standards began to allow LF as a newline too. As a result, operating systems differ in their definition of a newline. A newline is LF on Unix. Operating systems using CR LF include CP/M, DOS, OS/2 and Windows. Naturally, this caused an incompatibility. To solve the problem, control characters IND and NEL were added to the C1 area. This did not solve the issue, resulting in IND being removed later.
Note: NEL maps to the control character NL (New Line) in the EBCDIC character set used on IBM mainframes.“
EBCDIC is an encoding descended from punched cards and the six bit decimal code used with most IBMs of the late 1950s and early 1960s. Wikipedia has a great picture of such a punch card.
{kind=link}
__________________________________________________
Finally, in the early 1990s when it was becoming increasingly obvious that the Internet, and soon the burgeoning World Wide Web in particular, would require a character set that supported all multilingual text, Unicode was born. By the time Unicode hit version 1.1 in 1993, it included the majority of common European- and Asian-based characters as well as—surprise, surprise—a few new control characters of course:
“A paragraph separator–independent of how it is encoded–is used to indicate a separation between paragraphs. A line separator indicates where a line break alone should occur, typically within a paragraph. For comparison, line separators basically correspond to HTML
, and paragraph separators to older usage of HTML
(modern HTML delimits paragraphs by enclosing them in
…
).The Unicode Standard defines two unambiguous separator characters: U+2029 (PS) and U+2028 (LS). In Unicode text, the PS and LS characters should be used wherever the desired function is unambiguous.“
Yes, this surely made everything better.
__________________________________________________
Given the reality of reading CSVs, at best a loose convention with more interpretations and incarnations than even the newline, the most sanity-preserving path is usually to stick to the basic newlines (LF, CR+LF, CR) and call it a day, if you can get away with it.
But if one day you encounter a VT masquerading as a space in the text editor, or rescue some long-siloed database that was instructed by its departed master to delimit records with RS, perhaps you’ll recall the enigmatic history of these dust-gathering control characters.