
A lot shipped this cycle. Here's what changed and why it matters if you build on the Enigma graph.
We rebuilt entity clustering around the signals that usually decide whether two business records are actually the same company: address, person, EIN, and source quality. The total legal entity count moved from 104.5M to 103M, which is what we wanted. That's deduplication, not missing data, and ID churn stayed under 2%.
The practical effect is that downstream facts now attach to the right business more often. We added 200K brand-to-legal-entity links, which helps close one of the annoying gaps in KYB work: the business name a customer recognizes is often not the legal entity you need to verify.
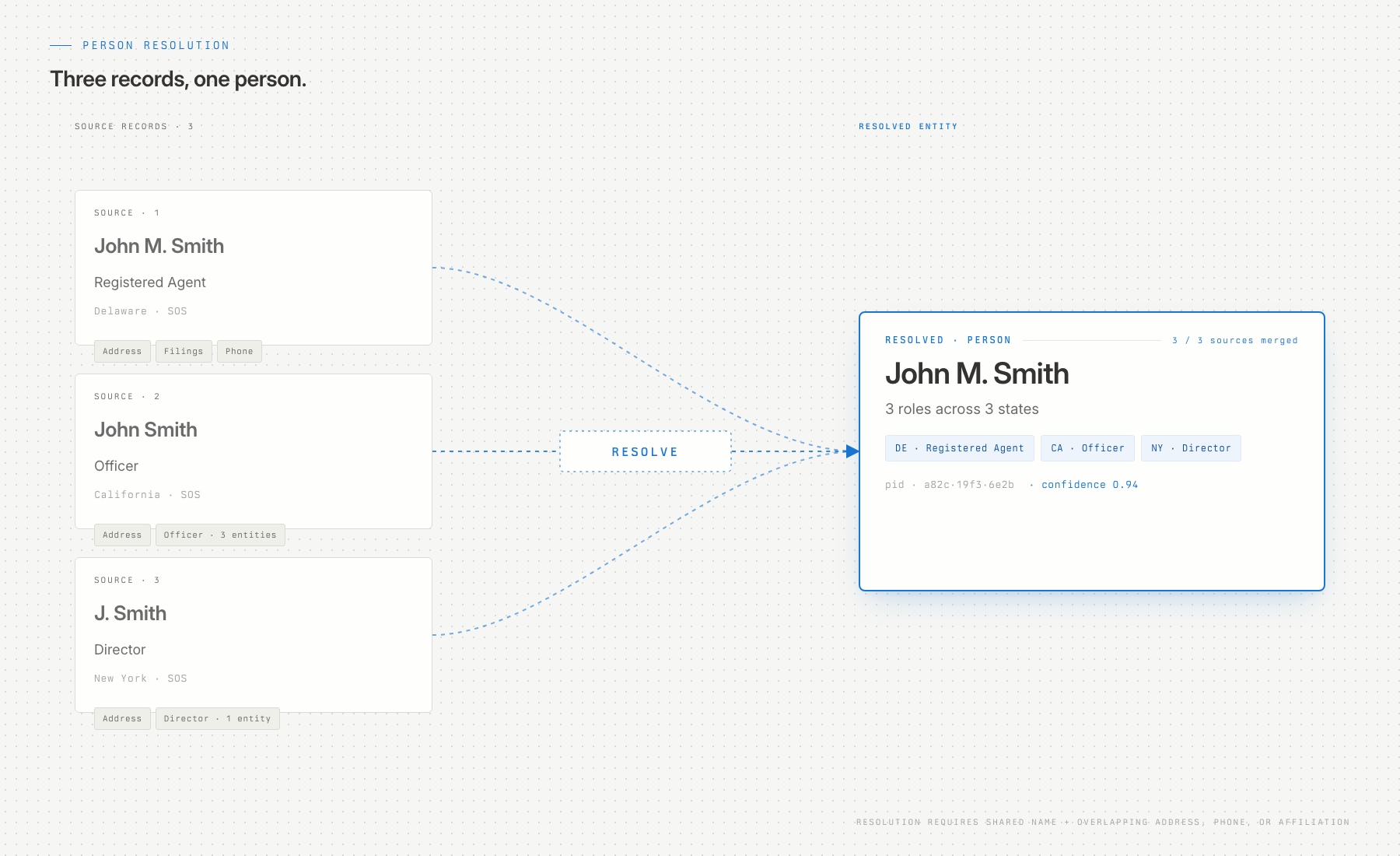
Until this release, a person listed as an officer in Delaware and a registered agent in California showed up as two unrelated records. There was no way to know they were the same person.
Now there is. Person resolution draws on government business registrations across all 52 U.S. jurisdictions, federal records including CMS and PACER, and licensed commercial datasets — resolved across sources into deduplicated person entities with canonical names. As of the most recent data release, that's 102.9 million resolved persons.
We're deliberately conservative with when we choose to merge person records. It requires a shared name plus overlapping auxiliary information: address, phone, business affiliation, or social media IDs. Over-resolution is under 1% in our validation sample. Under-resolution is under 10%, and we're actively working to improve it.
Beneficial ownership tracing, officer verification, fraud detection across corporate structures — all of that is now possible through the graph. Add LegalEntity.persons() to any existing legal entity query.
We'll publish a deeper dive on the cleaning methodology and validation approach separately.
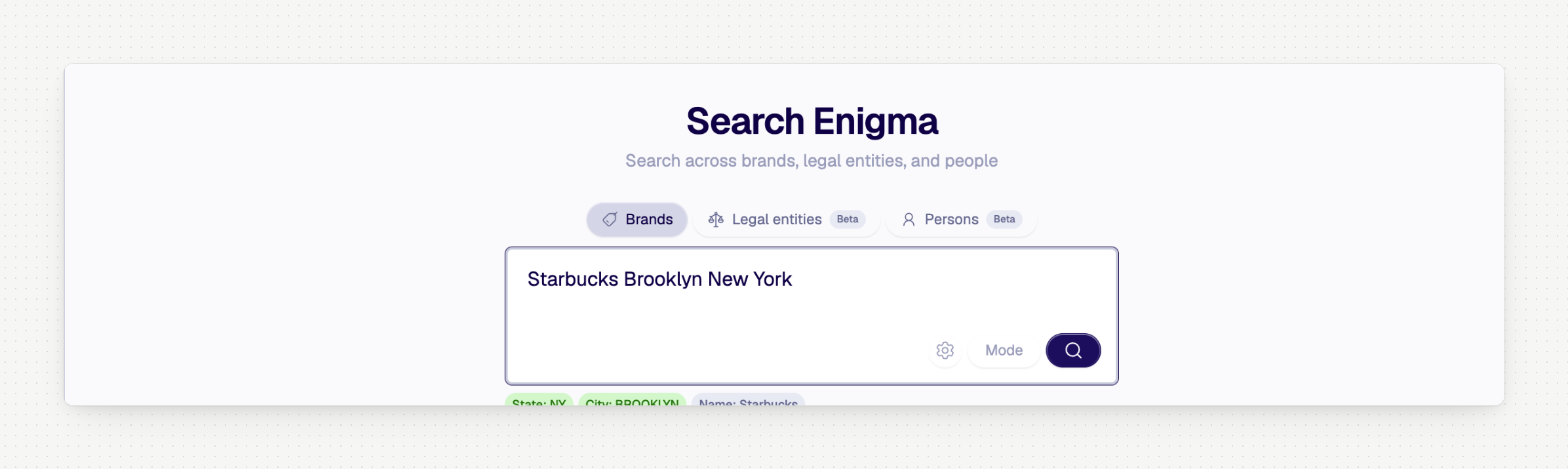
Console search got an upgrade. Type what you're looking for the way you'd say it — a business name, a city, a combination — and the search bar figures out which fields you mean. No dropdowns, no mode-switching, just type and go. If you'd rather specify fields manually, there's a toggle for that.
EIN coverage is hard because EINs aren't published cleanly or consistently, and brand names rarely line up perfectly with legal filings. We expanded brand-level EIN fill rate from 0.73% to 4.52% — roughly a 6x increase. Coverage skews toward Florida right now. We're adding more states every release cycle.
For KYB teams, this matters because TIN verification is one of the places where a thin business profile turns into manual review. More EINs at the brand level means fewer dead ends when the analyst starts with the business the customer gave them, not the legal entity buried three hops away.
We rebuilt the API Playground from scratch. The old version was a GraphQL editor with a schema drawer bolted on. Functional, but you had to already know the schema to get anything out of it.
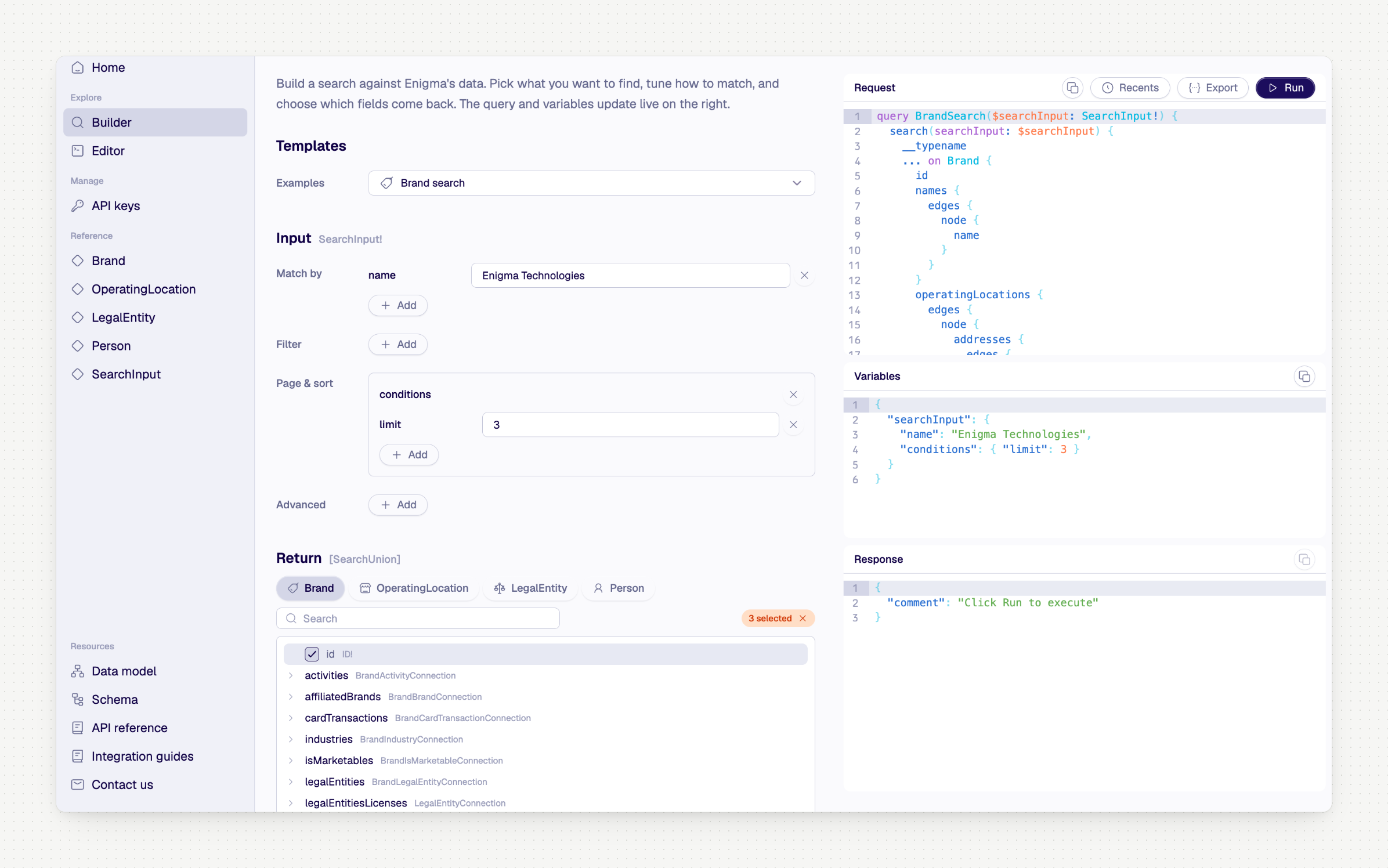
The new version works the other way around. Browse entity types, see what fields exist, click to add them to your query. Every field has a "copy snippet" button that gives you the full traversal path — edges → node and all — so you can paste it into your own code without hand-typing nested structures. There's a fuzzy search across all entity types, and the schema explorer matches on descriptions, not just field names. If you've ever spent 20 minutes hunting for the right connection type in a schema drawer, this is the fix.
You can still drop into the raw editor if you want it. Try it →
We changed the GovArchive MCP tool so full record detail is now opt-in. It used to return everything by default, which meant broad queries could overwhelm context windows and stall agent workflows at exactly the wrong time. Now you get lightweight results first and pull the full records only when you need them. Not glamorous, but very real: tools are only useful if they behave predictably under load.
We published four Claude Code skills: enigma-graphql, enigma-gov-archive, enigma-kyb, and enigma-screen. They're schema-validated, include worked examples, and live in a public repo at github.com/enigma-io/enigma-claude-plugins. The point isn't that we "support AI workflows." The point is that the same checks we expect from normal integration work now apply when an engineer is using an agent against Enigma data.
Industries in EnigmaDB now have hierarchical relationships. "Italian restaurant" is linked to "restaurant," and you can traverse between them via GraphQL and data delivery. That's the version analysts actually need when they want broad coverage without losing the ability to drill into specific business types.
Console search doesn't use the hierarchy yet — that's coming. For now, this is an API and data delivery feature. We're still refining the traversal semantics — check the documentation for current behavior.
Tax preparers spike in April. Ski resorts peak in January. Pool supply stores surge in June. Identifying these patterns at scale used to mean pulling months of transaction data and building your own model.
Two new attributes on brands and operating locations: gini_score measures how concentrated revenue is across months (higher = more seasonal). recurring_peak_month tells you when the peak hits. The index is built on three years of card transaction history and only surfaces consistent recurring peaks, not one-off spikes from a viral moment or a promo.
Precision: 91% at Gini >= 0.4 (100 manually labeled samples), 99% at >= 0.6, 100% in our validation set at >= 0.8. Coverage: 145,000 brands and 101,000 operating locations at Gini >= 0.4.
Available via GraphQL and data delivery.
Want to know more? Reach out to your account team or check documentation.enigma.com if anything here raises questions or interest.